Trabajo herramientas para la sustentación
de trabajos escritos
Tatiana Estefania Clavijo Garcia
Institución educativa distrital nueva Zelandia J.T
Bogotá D.C 27 de mayo de 2011
Trabajo herramientas para la sustentación
de trabajos escritos
Tatiana Estefania
Clavijo Gacia
1101
Carlos Romero
Informatica
Institución educativa distrital nueva Zelandia J.T
Bogotá D.C 27 de mayo de 2011
Contenido
Freemind……………………………………………
Cmaptools……………………………………………
Introducción
Este es un documento que elabore sobre mi aprendizaje de los programas.
FreeMind
Para hacer la instalación de freemind, se descarga el archivo de internet, porque es un software gratuito y sin restricciones, solo que para trabajar en él se requiere de un completo que es java, de lo contrario no se podría ser abierto para un trabajo completo.
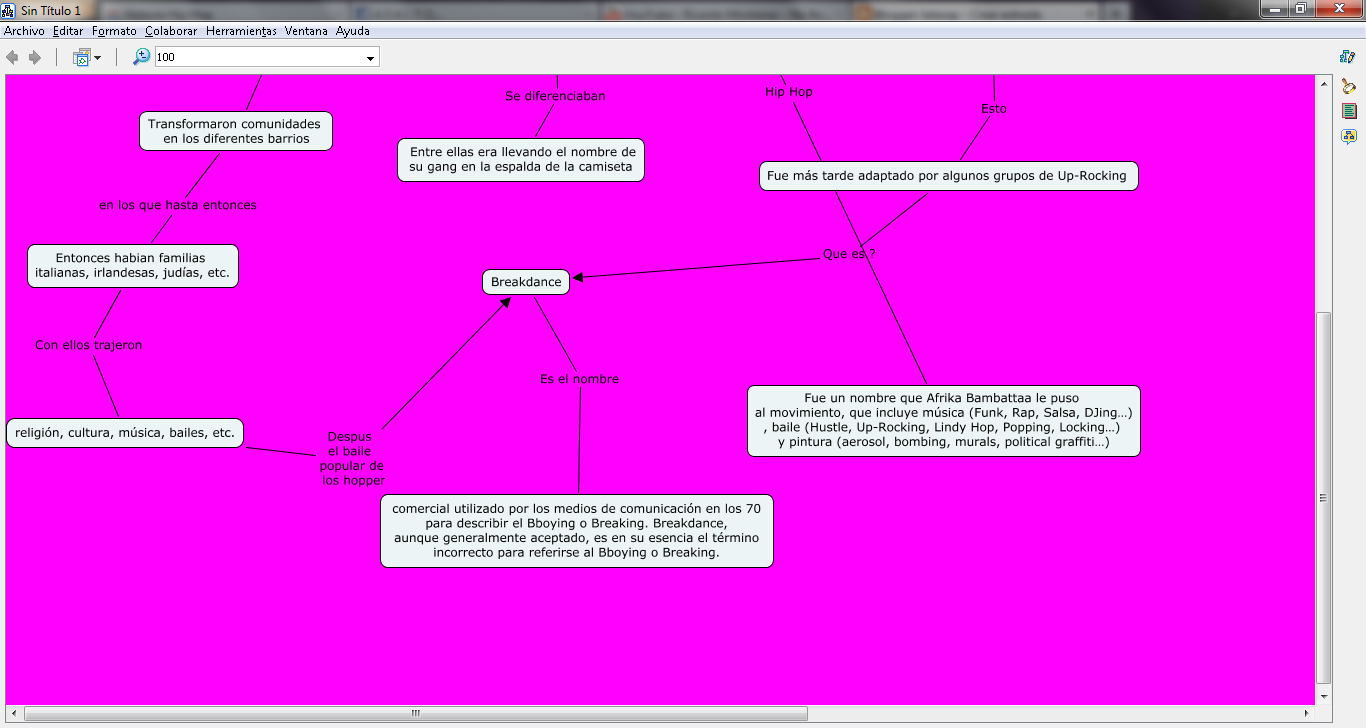
Es una herramienta de software que nos permite la elaboración de mapas mentales, es un programada de Java. Es una alternativa libre con la que podemos organizar nuestras ideas, la aplicación es útil en el análisis y recopilación de información o ideas, pues con él es posible generar mapas mentales.
FreeMind nos permite editar un conjunto de ideas en orden alrededor de un concepto central, las ideas se añaden una a una al mapa mental. Un mapa mental nos ayuda a representar palabras, ideas, tareas, u otros conceptos ligados y dispuestos alrededor de una palabra clave o de una idea central. Se utiliza para la generación, visualización, estructura, de las ideas, y como ayuda interna para el estudio, organización, solución de problemas, toma de decisiones y escritura. Es un diagrama de representación de palabras con conexiones entre las ideas de información ya que con freemind podemos ordenar nuestras diversas ideas. Presentando estas conexiones de una manera gráfica, estimula un acercamiento para cualquier mapa ya que es una organización de datos,
Un mapa mental es similar a un conjunto de palabras , pero sin restricciones formales en las clases de enlaces usados. Los elementos se arreglan según la importancia de los conceptos y se organizan en las agrupaciones y las ramas .La formulación gráfica puede ayudar a la memoria.
El único problema que le encuentro a éste software es que todavía no incluye la herramienta „deshacer“ ,el resto me gusta.